海天瑞聲DOTS-LLM大模型服務平臺正式發布,數據底座賦能大模型技術產業
由世界互聯網大會和浙江省人民政府主辦的2023年世界互聯網大會“互聯網之光”博覽會于11月7日在中國浙江烏鎮開幕。海天瑞聲CTO黃宇凱在“互聯網之光”博覽會上正式發布DOTS-LLM大模型服務平臺。該平臺提供大模型開發全生命周期管理服務,覆蓋從數據采標、數據管理、模型訓練、模型評測在內的全棧能力。為大模型企業提供更加高效卓越的數據處理服務,助力大模型產業的快速發展。

海天瑞聲CTO黃宇凱在“互聯網之光”博覽會現場 發布DOTS-LLM大模型數據服務平臺
大模型發展浪潮的背后是數據、算法、算力的合力推動。隨著數據處理技術的不斷發展,能夠獲取和處理的數據量更大、質量更高、種類更多,數據為大模型的訓練提供了豐富的“養分”。同時,大模型的發展也為數據的利用開辟了新的可能,使得我們能夠更有效地挖掘數據的價值,進一步推動人工智能領域的發展。
數據賦能大模型性能躍遷
數據采集階段
大模型的訓練需要大規模數據集,以確保模型的覆蓋性和準確性。這一階段的數據標注數量和質量都十分重要,需要確保訓練數據的準確性和可信度。
數據預處理階段
對數據進行清洗和去噪,以去除噪音和異常值,確保數據的質量。并進行特征提取和轉換,以使數據適合模型訓練,提高模型的性能和效率。這些步驟是構建高效、準確大模型的關鍵。
模型訓練階段
為了確保模型的準確性和泛化能力,需要無偏數據集,避免數據偏見導致模型偏差。此外,超參數調整也是至關重要的環節,通過調整和優化模型的超參數,我們可以獲得更好的訓練效果。同時也需要大規模的計算資源加速訓練過程。
模型評測階段
使用數據集對模型進行評測,以確保模型在未見過的數據上具有良好的泛化能力。同時,選擇和應用適當的評測指標,如知識性、安全性、邏輯推理能力等,來全面評測模型的性能。為了獲得更準確、可靠的評測結果,需要在大規模數據集進行評測,以確保模型在訓練和測試過程中的覆蓋性和準確性。
目前,大模型領域的數據處理仍面臨諸多挑戰。
首先,數據獲取和標注過程需要投入大量的人力物力,增加了開發成本。其次,由于版權數據及垂類數據收集難度較大,進一步加大了數據獲取的難度。此外,數據偏見和多樣性覆蓋不足的問題也不容忽視,會在一定程度上影響模型的性能和準確性。最后,如何在利用數據的同時保護個人隱私和數據安全,是大家重點關注的問題。為了更好的推動大模型數據領域的發展,亟需解決以上痛點問題。
DOTS-LLM 核心功能點
海天瑞聲DOTS-LLM大模型服務平臺匯集了海天瑞聲多年積累的行業經驗和專業技能,通過深度優化的算法技術,賦能大模型開發全生命周期管理。
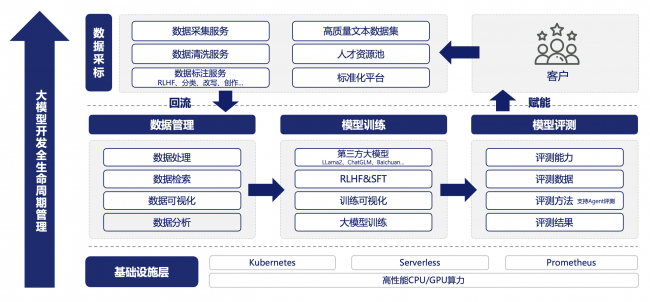
大模型開發全生命周期管理
數據采標
高質量文本數據集及專業數據服務
隨著數據需求急劇增長,安全合規的獲取數據變得愈發關鍵,同時也更具挑戰。卓越高效、安全合規的采標能力是海天瑞聲的核心技術之一。海天瑞聲以多年積累的數據采標能力為基礎,并通過標準化平臺進行精準的標記、清洗,支持RLHF、分類、改寫、生成等任務,為大模型的數據處理和模型訓練提供可靠的數據基礎。
數據管理
內置數據處理算法,高效精準的數據管理體驗
通過內置多種處理算法,顯著提升數據處理流程的效率。支持多維度條件檢索,使用戶能夠快速、準確地獲取特定數據,減少查找和篩選數據的時間。同時,該模塊還提供了豐富的可視化方案,幫助用戶更好地理解數據的特征、趨勢和關聯性。這使得用戶能夠更直觀地了解數據分布情況,并根據這些信息做出優化決策。
模型訓練
全面的模型訓練和管理體驗
海天瑞聲DOTS-LLM大模型服務平臺支持20多種第三方大型模型的接入。針對大模型應用場景,以高質量標注數據和SFT&RLHF等方法對大模型進行微調。同時,通過多種可視化方案,幫助用戶更好地理解模型訓練過程和決策依據,從而更好地調整模型參數和優化模型性能。此外該平臺還支持多機多卡并行訓練和增量訓練,以提高訓練效率。
模型評測
模型準確性和穩定性多維評測
海天瑞聲的專家團隊提供全面的模型評測服務,通過通用語言能力與安全可靠性兩大維度展開,主要涵蓋閱讀理解、邏輯推理、知識運用、生成創作、安全性、魯棒性六大能力以及19個子能力,以確保模型在不同場景下的穩健性和魯棒性。更好的驗證模型的實用性,并使其更加符合客戶的需求和預期。

作為國內領先的人工智能數據服務商,海天瑞聲一直致力于為人工智能企業提供高品質的數據。此次推出的DOTS-LLM大模型數據服務平臺,以期更好的滿足大模型企業在數據方面的需求。
未來,海天瑞聲將繼續深耕數據領域,不斷完善和拓展我們的服務,以應對快速變化的數據環境,助力客戶在大模型時代取得更大的成功,為人工智能產業提供更加堅實的數據基石,推動人工智能技術的快速發展。
免責聲明:市場有風險,選擇需謹慎!此文僅供參考,不作買賣依據。
標簽:














 瞅一瞅,外灘亮相了這些“黑科技”!
瞅一瞅,外灘亮相了這些“黑科技”!
 華為Mate X5和Mate 60 Pro+開啟預售;中石油收購普天新能源;螞蟻集團發布金融大模型|Do早報
華為Mate X5和Mate 60 Pro+開啟預售;中石油收購普天新能源;螞蟻集團發布金融大模型|Do早報
 阿信西安演唱會吸氧
阿信西安演唱會吸氧